近日,中国科学院合肥物质院智能所运动健康团队丁增辉研究员联合芝加哥大学、卡内基梅隆大学团队,在国际上首次提出一种多模态大模型视觉-语言预训练方法RankCLIP,入选国际计算机视觉顶会ICCV 2025,彰显了智能所在人工智能前沿领域的创新实力。智能所博士研究生张一鸣为第一作者。
自2021年OpenAI发布CLIP以来,视觉-语言模型始终依赖“图像-文本一对一配对”的对比学习。尽管CLIP在零样本分类、图文检索等任务中表现卓越,但其“硬对齐”方式也带来明显局限:模型仅能判断“是否匹配”,却无法理解“谁与谁更接近”。
RANKCLIP的核心突破在于:受人脑不同感官皮层和联合皮层跨模态联合表征机制启发,将训练目标从Clip的“配对判断”升级为“排序学习”,构建图像与文本之间的全局排序分布,并通过最大化排序一致性似然来优化模型。该方法无需额外数据或计算资源,即可作为“即插即用”模块融入现有CLIP系列模型,被大会程序委员会评价为“有望重新定义视觉-语言预训练范式的突破性工作”。
该方法拥有三大技术创新:一是实现跨模态排序一致性,RankCLIP采用Plackett-Luce排序模型,将这一软约束转化为可导损失函数,实现全局排序优化;二是实现模态内排序一致性,除了跨模态关系,RANRankCLIPKCLIP首次将图像与文本各自内部的语义排序纳入训练目标,有效挖掘了模态内的潜在语义结构;三是设计动态权重系数,渐进式权重策略使排序损失在训练初期受噪声影响较大,团队设计动态权重系数,使其在训练过程中从零逐渐增大,既避免干扰初期的对比学习,又在后期充分释放排序信号。
实验结果证实RankCLIP全面刷新零样本基准。零样本分类:在ImageNet1K上,RankCLIP的Top-1准确率达到10.16%,显著优于CLIP(9.06%)、CyCLIP(9.40%)和ALIP(9.71%)。跨模态检索:在MS-COCO图像-文本检索任务中,RankCLIP在多项召回率指标上均优于基线模型。分布偏移鲁棒性:在ImageNet-V2和ImageNet-R等具有自然分布偏移的数据集上,RankCLIP表现出更强的泛化能力。线性探测:在10个图像分类数据集上的线性探测实验中,RankCLIP平均准确率最高,显示其表征学习能力的优越性。
该创新成果的提出有利于推动医疗诊断、具身智能等关键领域的智能化升级,加速普惠AI技术的规模化落地,证明了算法创新优于算力堆叠,展现了我国在大模型底层算法前沿研究领域的实力,也为全球AI技术的发展贡献中国智慧。该研究得到了国家重点研发计划计划、安徽省科技攻坚等项目的支持。
ICCV(IEEE/CVF International Conference on Computer Vision)是计算机视觉领域最具影响力的国际顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。该会议每两年举办一次,由美国电气和电子工程师学会(IEEE)与计算机视觉基金会(CVF)联合主办。
论文链接:
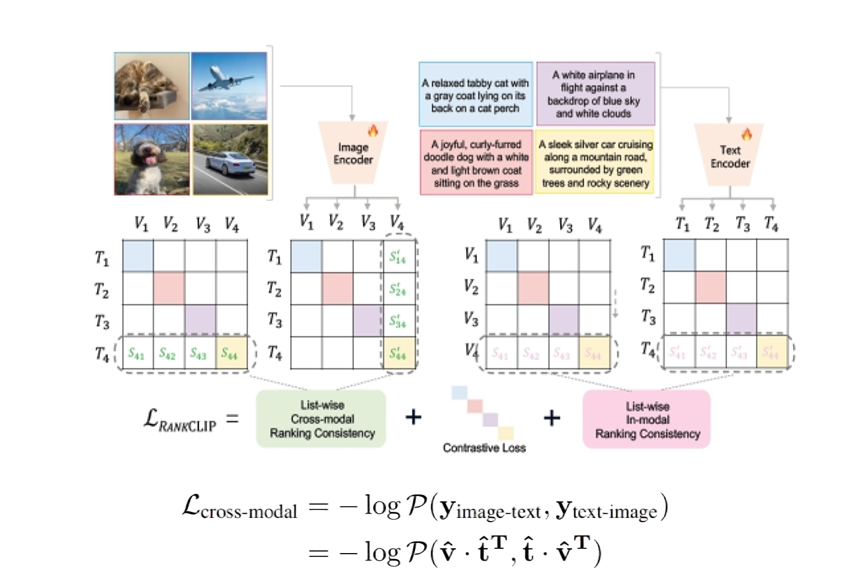
图 RankCLIP技术概览




