近日,中国科学院合肥物质院健康所表观基因组团队谷红仓研究员、张帆研究员指导研发出一种基于表型感知对比学习的抗体语言模型——BCRInsight。该模型通过对海量序列的自监督学习,成功实现了对复杂免疫信号的深度解码,在抗体结合位点预测及B细胞亚群分析等任务上均达到了当前最佳性能。该研究成果以“BCRInsight: an antibody language model to decode biological signals from BCR sequences”为题,发表于Briefings in Bioinformatics。
B细胞受体(BCR)免疫库蕴含着极其丰富的生物学信号,它不仅决定了抗原识别的特异性,更像是一部记录B细胞激活、成熟及演化轨迹的精密“史书”。然而,抗体序列中蕴含的语义逻辑极其复杂,传统的生物信息学方法往往难以捕捉其中高阶、非线性的语义依赖。同时,尽管单细胞测序技术能够提供高精度的细胞信息,但高昂的单细胞测序成本严重限制了其在大规模临床队列研究中的应用。因此,亟需一种低成本、高效且能深度提取复杂生物语义的创新计算工具。
针对上述挑战,研究团队构建了基于12层Transformer编码器、拥有约8600万个可训练参数的深度学习框架BCRInsight。与传统仅依赖掩码的语言模型不同,团队创新性地引入了“表型感知对比学习”策略,并在8000万条人类BCR序列的大规模数据集上完成了预训练。在输入设计上,模型将氨基酸序列与基因注释等元数据进行类似自然语言处理中“句子对”的联合编码。实验结果显示,BCRInsight展现出卓越的泛化与表征能力:在B细胞亚群分析中,模型能够从高度复杂的bulk BCR-seq数据中低成本地反卷积出B细胞亚群组成比例,准确率超越了现有的代表性序列预测模型;在抗体结合位点(Paratope)预测测试中,其AUROC高达0.962,在与9种国际最先进的方法横向对比中取得领先。更为突破的是,模型在未接触任何三维结构监督信号的条件下,其自注意力机制“涌现”出了对三维结构的感知能力,聚焦于决定抗原识别的关键HCDR3环区及结构支撑位点。这一研究为实现从“阅读免疫语言”到“编写免疫语言”的跨越,以及指导疾病特异性抗体的人工设计与优化提供了强大引擎。
硕士研究生赵海龙、博士研究生娄上和李徐华为论文共同第一作者。该研究工作得到了安徽省科技重大专项、安徽省自然科学基金、“慢性非传染性疾病”国家科技重大专项以及中国科学院合肥物质院种子基金等项目的支持。
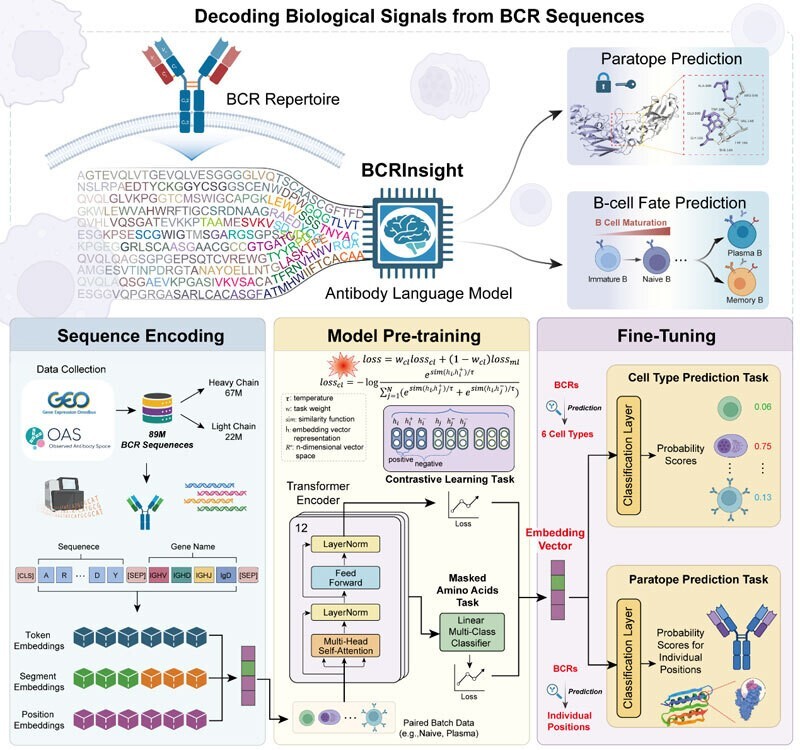
图1. BCRInsight模型框架




